Backups serveurs
Projet personnel
Une fois que j’ai créé et configuré mon Proxmox (voir ici), il a fallu que je mette en place une sauvegarde pour mes différents services. Je vais parler ici de la sauvegarde de mes sites web, les autres services sont sauvegardés de manière similaire.
Où faire la sauvegarde ?
La première problématique était de trouver un endroit où je peux sauvegarder mes différents fichiers. Cet endroit doit respecter certaines conditions :
-
Il ne doit pas être physiquement dans la même localisation que le serveur Proxmox.
-
Afin de préserver la souveraineté de mes données, il serait préférable que ce serveur ne soit pas la propriété d’une grande entreprise, telle les GAFAM.
-
Finalement, il faut aussi suffisamment d’espace disque afin de stocker mes différents fichiers.
Suite à des discutions avec différentes personnes, je me suis tourné vers le serveur d’une connaissance, qui m’a gentiment proposé d’héberger mes sauvegardes chez lui.
Je peux donc être sûr que mes données soient dans un endroit différent de mon serveur principal et je reste également maître de la souveraineté de mes données.
Concernant le dernier point, je dispose maintenant de largement assez d’espace disque pour stocker toutes mes sauvegardes.
Comment faire la sauvegarde ?
Maintenant que j’ai pu trouver un endroit, où je peux sauvegarder mes données, il me restait à trouver de quelle façon le faire.
Pour cela, je me suis rapidement tourné vers Rsync. C’est une application en ligne de commande, permettant de pouvoir facilement copier des fichiers d’un serveur à un autre, en ne copiant que les fichiers ayant changé.
J’ai fait ce choix pour différentes raisons :
-
Rsync est déjà installé sur mes différentes machines.
-
C’est un outil que je connais plutôt bien et que j’utilise couramment.
-
Il utilise le SSH, ce qui me permet de me connecter facilement à l’autre serveur, sans avoir à installer une autre application.
On m’a créé un utilisateur sur le serveur distant, j’ai donc pu commencer à écrire mes différents scripts.
Sauvegarde des différents fichiers
Fichiers web et configurations
Pour commencer, j’ai créé un script permettant de sauvegarder les différents fichiers des sites web, ainsi que les configurations des vhosts.

Ce script permet la sauvegarde des fichiers.
J’ai ensuite ajouté ce script dans les tâches CRON, afin de lancer la sauvegarde automatiquement.
Bases de données
Une fois, la partie la plus simple réalisée, il fallait maintenant que je mette en place la sauvegarde des bases de données, ainsi que sa compression. Il fallait également que je supprime les archives les plus anciennes pour éviter de surcharger les deux serveurs.
Pour éviter de mettre le mot de passe d’un utilisateur du SGBD dans le script, j’ai utilisé 2 utilisateurs Unix, l’un ayant les accès à la base de données, l’autre faisant le transfert via Rsync. J’ai donc créé 2 scripts.
Le premier script, étant un peu long, je vais l’expliquer au fur et à mesure.
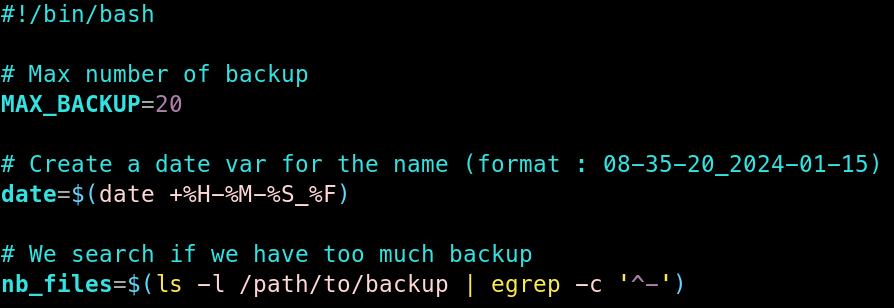
J’ai commencé par définir différentes variables :
-
MAX_BACKUP : une constante contenant la quantité maximum de sauvegardes à garder.
-
date : une variable stockant la date actuelle pour nommer les fichiers.
-
nb_files : une variable indiquant le nombre de fichiers de backup actuellement dans le dossier.
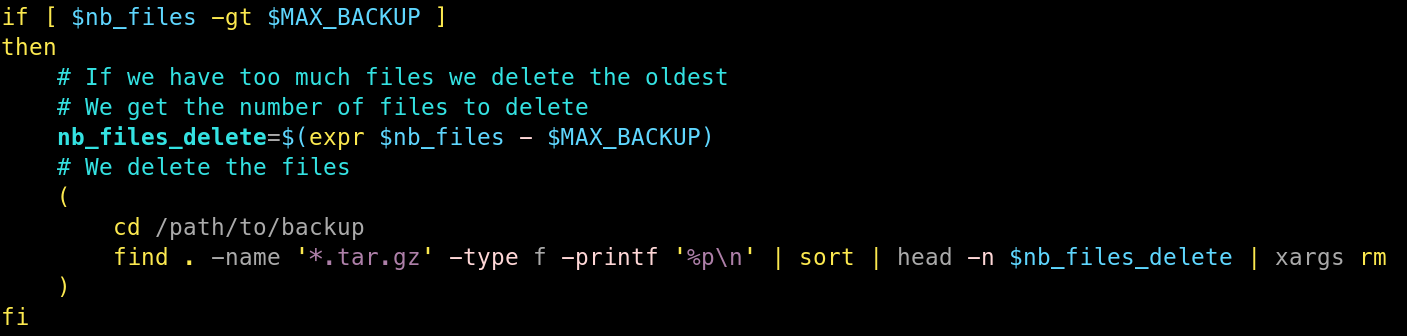
J’ai ensuite créé une condition, qui si le nombre de fichiers de sauvegarde est supérieur au maximum autorisé, va supprimer les fichiers en trop en partant des plus anciens.
Pour supprimer les fichiers les plus anciens, je commence par chercher le nombre de sauvegardes à supprimer via une soustraction du nombre de fichiers par le maximum de sauvegardes autorisées.
Je vais ensuite utiliser find, afin de récupérer les archives de sauvegarde, que je vais trier via sort, pour avoir les plus anciens tout en haut. Par la suite, je vais récupérer via head uniquement les fichiers à supprimer. Finalement, je vais utiliser un xargs, me permettant de boucler sur les fichiers en trop pour les supprimer.
Ça peut paraître un peu complexe de premier abord, mais c’est une solution tenant sur une ligne et utilisant seulement 5 commandes natives. C’est donc plutôt léger et pas trop compliqué à débugger en cas de soucis.
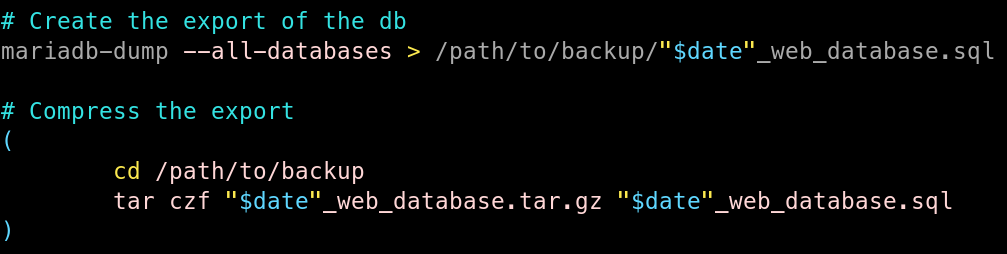
Ensuite nous voici dans la partie concrète de la sauvegarde des bases de données.
Dans un premier temps, j’ai utilisé mariadb-dump afin de faire un export des bases de données, dans un fichier SQL contenant la date dans son nom.
Ensuite, je vais compresser le fichier SQL, dans une archive TAR compressée avec GZIP, un tar.gz.
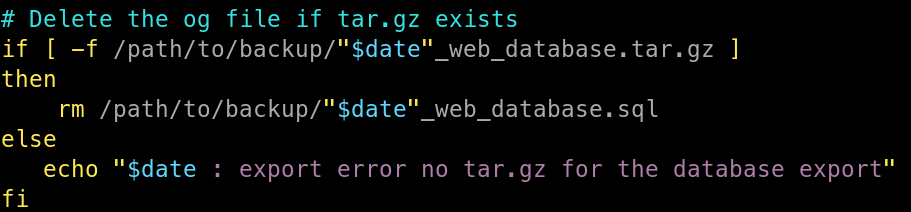
Finalement, je vais vérifier que l’archive tar.gz a bien été créée, si cela est le cas, je supprime le fichier SQL original, sinon j’envoie une erreur dans la sortie standard.
Une fois l’export de la base de données terminé, je l’envoie vers le serveur via Rsync, avec un script similaire au précédent.
Ces deux scripts sont lancés par deux utilisateurs différents, via deux tâches CRON.
Le serveur de sauvegarde, a lui aussi une tâche CRON permettant de supprimer les archives les plus anciennes, une fois le nombre maximum atteint, de façon similaire au script d’export des bases de données.
Conclusion
Voilà, maintenant mon serveur sauvegarde automatiquement les fichiers importants liés aux sites web. Les autres sont aussi sauvegardés d’une manière similaire.
Certes ce n’est pas une solution de sauvegarde extrêmement poussée, mais elle convient parfaitement à mes besoins. Elle m’a également permis d’écrire quelques scripts fun 😁 !
Merci à ces deux artistes de Flaticon :
DinosoftLabs : https://www.flaticon.com/fr/icones-gratuites/serveur
Souayang : https://www.flaticon.com/fr/icones-gratuites/la-fleche